SELECTCOUNT(*) FROM Student; SELECTCOUNT(*) AS 学生人数 FROM Student;
SELECTCOUNT(Major) AS 学生专业数 FROM Student; SELECTCOUNT(DISTINCT Major) AS 学生专业数 FROM Student;
SELECTMIN(BirthDay) AS 最大年龄出生日期, Max(BirthDay) AS 最小年龄出生日期 FROM Student;
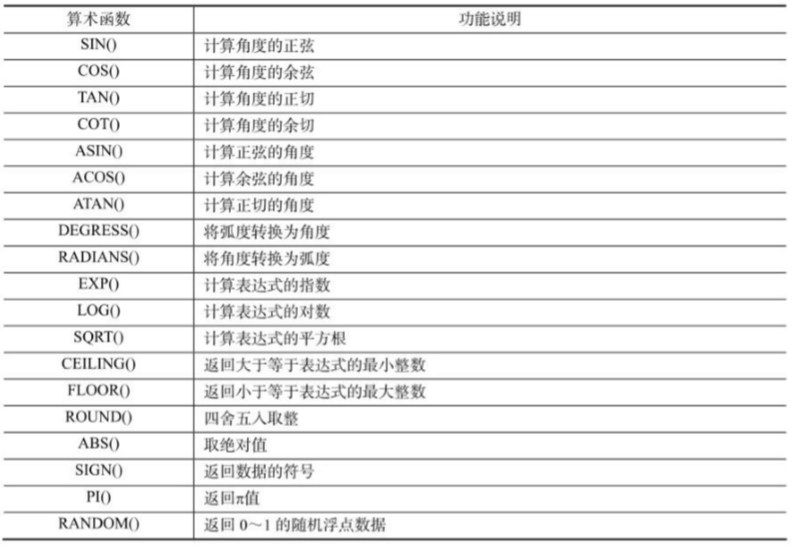
算数函数
字符串函数
时间日期函数
数据类型转换函数
子查询
1 2 3 4 5 6 7
SELECT TeacherID, TeacherName, TeacherTitle FROM Teacher WHERE CollegeID IN (SELECT CollegeID FROM College WHERE CollegeName=’计算机学院’) ORDERBY TeacherID;
数据控制
GRANT赋予权限
1 2 3
GRANT <权限列表> ON <数据库对象> TO <用户或角色> [ WITHGRANTOPTION ]; > GRANTSELECT, INSERT, UPDATE, DELETEONRegisterTORoleS;
REVOKE收回权限
1 2 3
REVOKE <权限列表> ON <数据库对象> FROM <用户或角色> ; > REVOKEDELETEONRegisterFROMRoleS;
DENY拒绝授权
1 2 3
DENY <权限列表> ON <数据库对象> TO <用户或角色> ; > DENY DELETEON Teacher TO RoleT;
视图
视图创建
1 2 3 4 5 6
CREATEVIEW <视图名>[(列名1),(列名2),…] AS <SELECT查询>; > CREATEVIEW BasicCourseView ASSELECT CourseName, CourseCredit, CoursePeriod, TestMethod FROM Course WHERE CourseType=’基础课’;
视图删除
1 2 3
DROPVIEW <视图名>; > DROPVIEW BasicCourseView;
视图使用
1 2 3 4 5
CREATEVIEW DataBaseCourseView ASSELECT C.CourseName AS 课程名称, S.StudentID AS 学号, S.StudentName AS 姓名 FROM Course AS C, Plan AS P, RegisterAS R, Student AS S WHERE C.CourseID=P.CourseID AND C. CourseName=’数据库原理及应用’ AND P.CoursePlanID=R.CoursePlanID AND R.StudentID=S.StudentID; > SELECT * FROM DataBaseCourseView;
CREATEORREPLACEFUNCTION countRecords () RETURNSintegerAS $count$ DECLARE countinteger; BEGIN SELECTcount(*) INTOcountFROM Student; RETURN count; END; $ count $ LANGUAGE plpgsql;
触发器编程
1 2 3 4 5 6 7
CREATE [CONSTRAINT] TRIGGERname { BEFORE | AFTER | INSTEAD OF } { event [ OR ...] } ON table_name [ FROM referenced_table_name ] [ FOR [ EACH ] { ROW | STATEMENT } ] [ WHEN (condition) ] EXECUTEPROCEDURE function_name ( arguments )
创建触发器
存在所依赖的表或视图
编写触发器函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
CREATEORREPLACEFUNCTION score_audit() RETURNSTRIGGERAS $score_audit$ BEGIN IF (TG_OP = 'DELETE') THEN INSERTINTO Audit_score SELECTuser, old.sid, old.cid, now(), OLD.score ; RETURN OLD; ELSIF (TG_OP = 'UPDATE') THEN INSERT INTO Audit_score SELECT user, old.sid, old.cid, now(), OLD.score , new.score where old.sid=new.sid and old.cid=new.cid; RETURN NEW; ELSIF (TG_OP = 'INSERT') THEN INSERT INTO Audit_score SELECT user, new.sid, new.cid, now(),null, new.score; RETURN NEW; END IF; RETURN NULL; END; $score_audit$ LANGUAGE plpgsql;